Building Effective RAG Systems with LangChain and FAISS
Retrieval-Augmented Generation (RAG) has become a cornerstone technique in modern AI applications, especially when working with Large Language Models (LLMs). In this post, I'll share my experience building RAG systems at Bank Alfalah and how you can implement your own using LangChain and FAISS.
What is RAG?
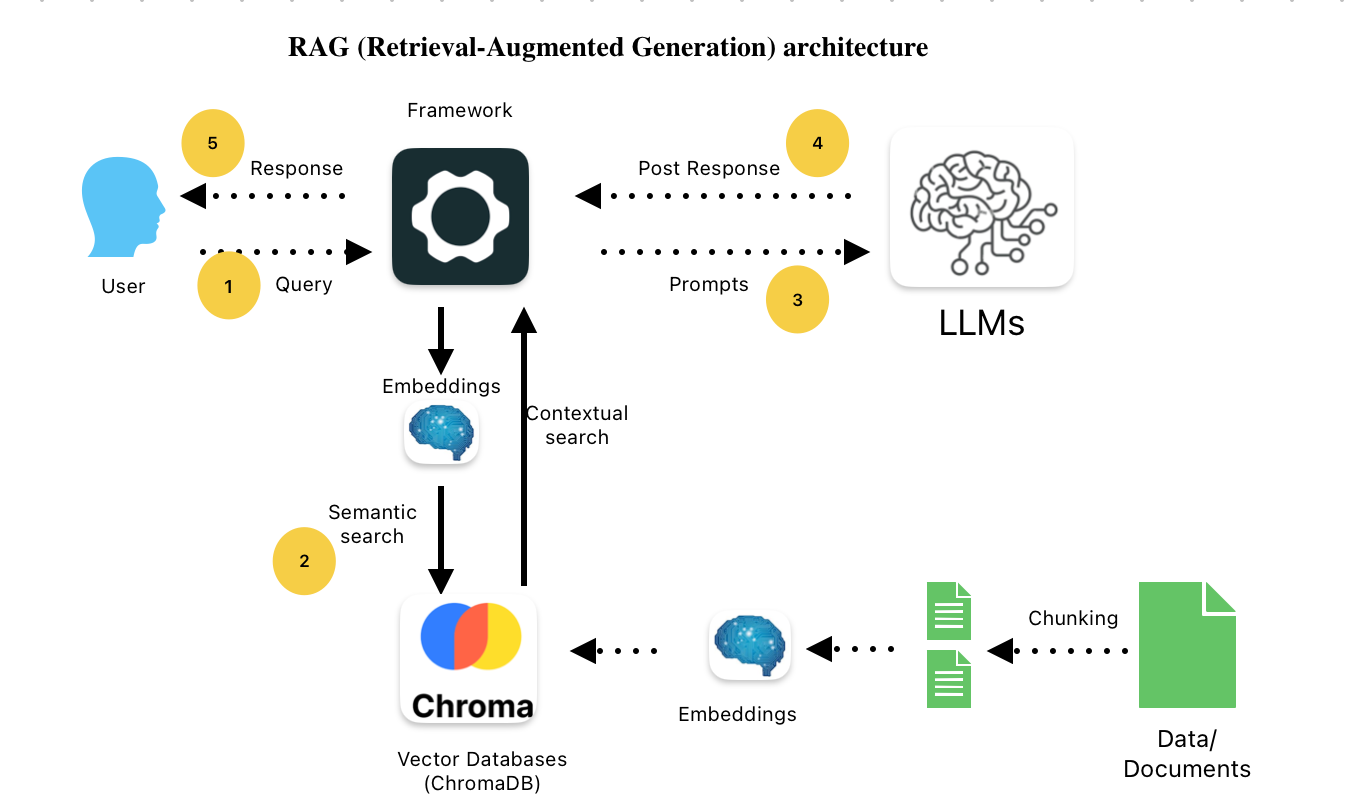
RAG combines the power of retrieval-based systems with generative AI. Instead of relying solely on an LLM's internal knowledge (which may be outdated or incomplete), RAG systems first retrieve relevant information from a knowledge base and then use that information to generate more accurate, up-to-date responses.
Key Components of a RAG System
- Document Processing: Converting various document formats into chunks suitable for embedding
- Vector Database: Storing and efficiently retrieving document embeddings (we'll use FAISS)
- Retrieval Logic: Finding the most relevant documents for a given query
- Generation: Using an LLM to generate responses based on retrieved context
Implementation with LangChain and FAISS
Here's a simplified example of how to implement a RAG system using LangChain and FAISS:
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Load documents
loader = DirectoryLoader("./documents/", glob="**/*.pdf")
documents = loader.load()
# 2. Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
texts = text_splitter.split_documents(documents)
# 3. Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(texts, embeddings)
# 4. Create retrieval chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = OpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 5. Query the system
query = "What are the key features of our new product?"
response = qa_chain.run(query)
print(response)
Optimizing RAG Performance
In my experience at Bank Alfalah, we found several ways to optimize RAG performance:
- Chunk Size Tuning: Finding the right balance between context and specificity
- Hybrid Search: Combining semantic search with keyword-based approaches
- Query Reformulation: Preprocessing user queries for better retrieval
- Metadata Filtering: Using document metadata to narrow search scope
Real-World Applications
We've successfully deployed RAG systems for:
- Customer Service Chatbots: Providing accurate responses based on policy documents
- Internal Knowledge Bases: Helping employees find information across thousands of documents
- Compliance Assistance: Ensuring responses adhere to banking regulations
Conclusion
RAG systems represent a powerful approach to enhancing LLM capabilities with domain-specific knowledge. By combining the retrieval power of vector databases with the generative capabilities of LLMs, we can build AI systems that are more accurate, up-to-date, and useful in real-world applications.
In future posts, I'll dive deeper into advanced RAG techniques like multi-query retrieval, reranking, and hybrid search implementations.