Optimizing Computer Vision Inference with TensorRT and NVIDIA Triton
In the world of computer vision deployment, inference speed is often as critical as model accuracy. At Bank Alfalah, we faced the challenge of deploying YOLOv8 models across 150+ ATMs while maintaining real-time performance. This post shares our journey of optimizing inference using TensorRT and NVIDIA Triton.
The Challenge
Our initial deployment of YOLOv8 for ATM monitoring had a latency of approximately 600ms per frame, which was too slow for real-time analysis. We needed to reduce this significantly while maintaining detection accuracy.
Enter TensorRT
NVIDIA TensorRT is an SDK for high-performance deep learning inference that includes a deep learning optimizer and runtime that delivers low latency and high throughput.
Here's how we converted our PyTorch YOLOv8 model to TensorRT:
from ultralytics import YOLO
# Load the PyTorch model
model = YOLO("yolov8m.pt")
# Export to ONNX format with dynamic batch size
model.export(format="onnx", dynamic=True)
# Convert ONNX to TensorRT using trtexec
# This is typically done via command line:
# trtexec --onnx=yolov8m.onnx --saveEngine=yolov8m.engine --fp16
The FP16 precision gave us a good balance between accuracy and speed. For models where we could tolerate some accuracy loss, we even experimented with INT8 quantization.
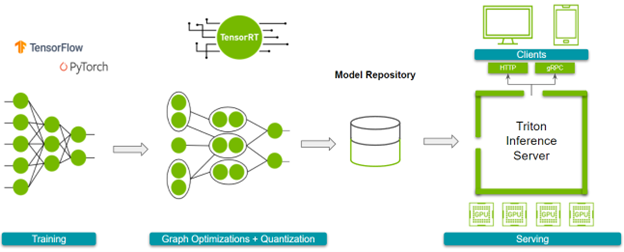
Scaling with NVIDIA Triton Inference Server
While TensorRT significantly improved single-instance performance, we needed a solution to scale across multiple ATMs and handle varying loads. NVIDIA Triton Inference Server was the perfect fit.
Triton provides a standardized way to deploy models from multiple frameworks (TensorRT, TensorFlow, PyTorch, etc.) and offers advanced features like dynamic batching, concurrent model execution, and model ensembles.
Our Triton configuration looked something like this:
name: "yolov8"
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "images"
data_type: TYPE_FP32
dims: [ 3, 640, 640 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ -1, -1 ]
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
max_queue_delay_microseconds: 5000
}
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0 ]
}
]
Results
After implementing TensorRT and NVIDIA Triton, we achieved remarkable improvements:
- Latency Reduction: From 600ms to under 100ms per frame (83% reduction)
- Throughput Increase: From 1.7 FPS to 10+ FPS
- GPU Utilization: Improved from 30% to 80%
- Scalability: Able to handle multiple ATM streams on a single RTX 4090
Client Implementation
On the client side, we used the Triton Python client to send frames for inference:
import tritonclient.http as httpclient
import numpy as np
import cv2
client = httpclient.InferenceServerClient(url="localhost:8000")
def process_frame(frame):
# Preprocess image
input_image = cv2.resize(frame, (640, 640))
input_image = input_image / 255.0 # Normalize
input_image = np.transpose(input_image, (2, 0, 1)) # HWC to CHW
input_image = np.expand_dims(input_image, axis=0).astype(np.float32)
# Create input tensor
inputs = [httpclient.InferInput("images", input_image.shape, "FP32")]
inputs[0].set_data_from_numpy(input_image)
# Get results
results = client.infer("yolov8", inputs)
output = results.as_numpy("output0")
# Process detections
# ...
return processed_frame
Lessons Learned
- Profile Before Optimizing: Understand where bottlenecks exist in your pipeline
- Batch Size Matters: Find the optimal batch size for your specific hardware
- Precision Tradeoffs: Balance between FP32, FP16, and INT8 based on accuracy requirements
- End-to-End Optimization: Consider the entire pipeline, not just the model inference
Conclusion
By leveraging TensorRT and NVIDIA Triton, we transformed our computer vision system from a proof-of-concept to a production-ready solution deployed across all Bank Alfalah ATMs. The optimized system not only improved performance but also reduced infrastructure costs by allowing more efficient hardware utilization.
In future posts, I'll dive deeper into specific optimization techniques like model pruning, knowledge distillation, and custom CUDA kernels for even greater performance improvements.